Generative AI has made rapid advancements in recent years, achieving unprecedented capabilities in multimodal understanding and code generation. This enabled a brand new paradigm of front-end development, where multimodal LLMs can potentially convert visual designs into code implementations directly, thus automating the front-end engineering pipeline. In this work, we provide the first systematic study on this visual design to code implementation task (dubbed as Design2Code). We manually curate a benchmark of 484 real-world webpages as test cases and develop a set of automatic evaluation metrics to assess how well current multimodal LLMs can generate the code implementations that directly render into the given reference webpages, given the screenshots as input. We develop a suit of multimodal prompting methods and show their effectiveness on GPT-4V and Gemini Vision Pro. We also finetune an open-source Design2Code-18B model that successfully matches the performance of Gemini Pro Vision. Both human evaluation and automatic metrics show that GPT-4V is the clear winner on this task, where annotators think GPT-4V generated webpages can replace the original reference webpages in 49% cases in terms of visual appearance and content; and perhaps surprisingly, in 64% cases GPT-4V generated webpages are considered better than even the original reference webpages. Our fine-grained break-down metrics indicate that open-source models mostly lag in recalling visual elements from the input webpages and in generating correct layout designs, while aspects like text content and coloring can be drastically improved with proper finetuning.
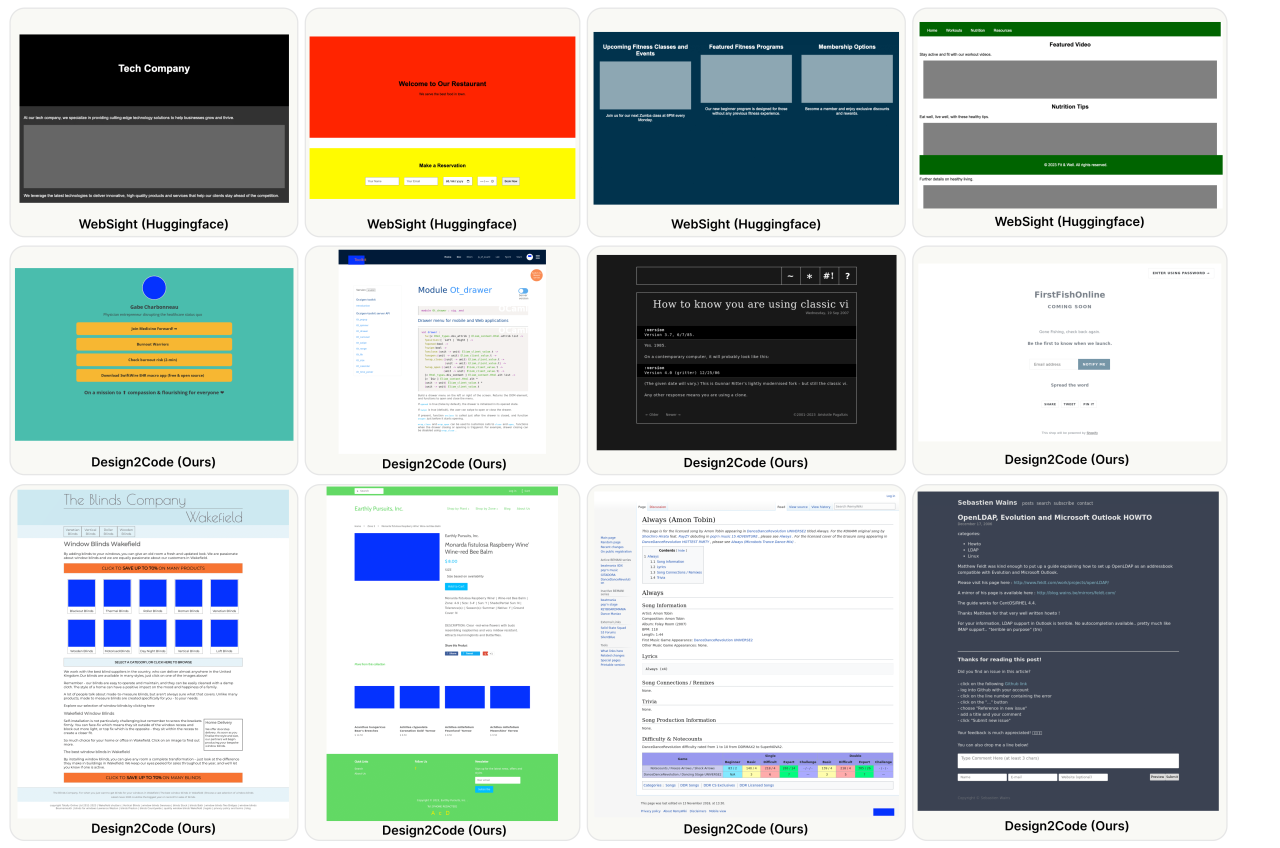
We show some examples from our benchmark (for evaluation purpose; bottow two rows) in comparison with the synthetic data created by Huggingface (for training purpose; first row). Our benchmark contains diverse real-world webpages with varying levels of complexities. (Image files are replaced with a placeholder blue box.)
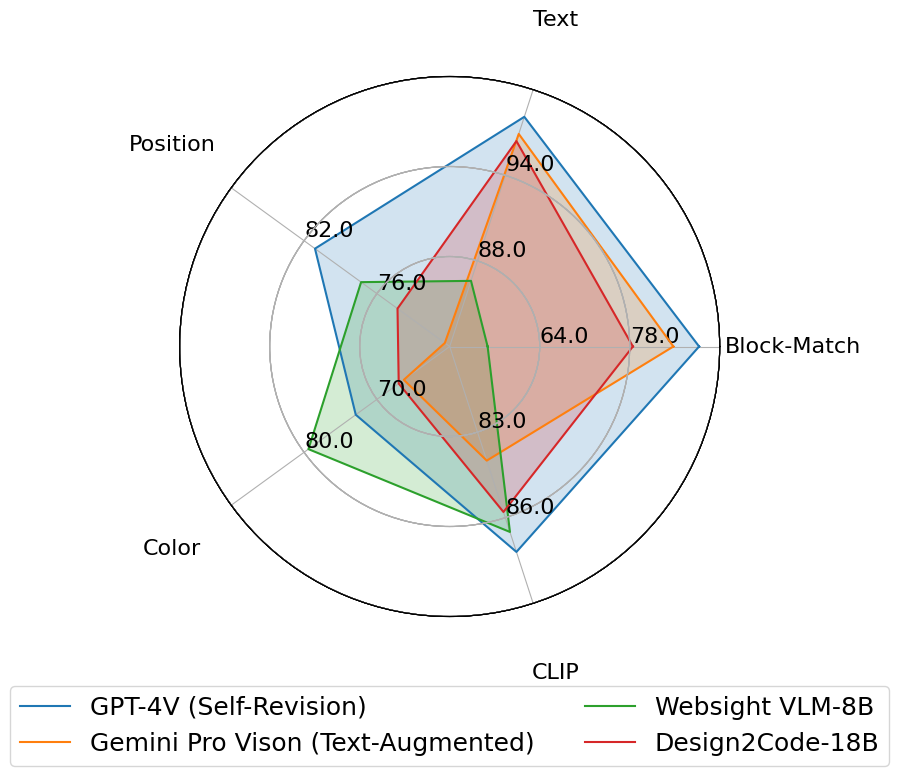
Benchmark Performance: Automatic Metrics
For automatic evaluation, we consider high-level visual similarity (CLIP) and low-level element matching (block-match, text, position, color). We compare all the benchmarked models along these different dimensions.
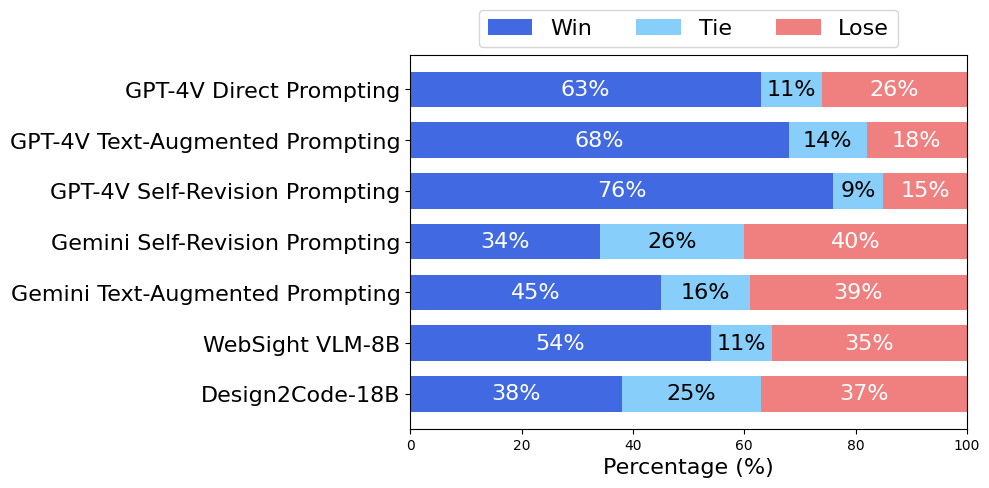
Benchmark Performance: Human Evaluation
We recruit human annotators to judge pairwise model output preference. The Win/Tie/Lose rate against the baseline (Gemini Pro Vision Direct Prompting). We sample 100 examples and ask 5 annotators for each pair of comparison, and we take the majority vote on each example.
Model Comparison Examples
We present some case study examples to compare between different prompting methods and different models.


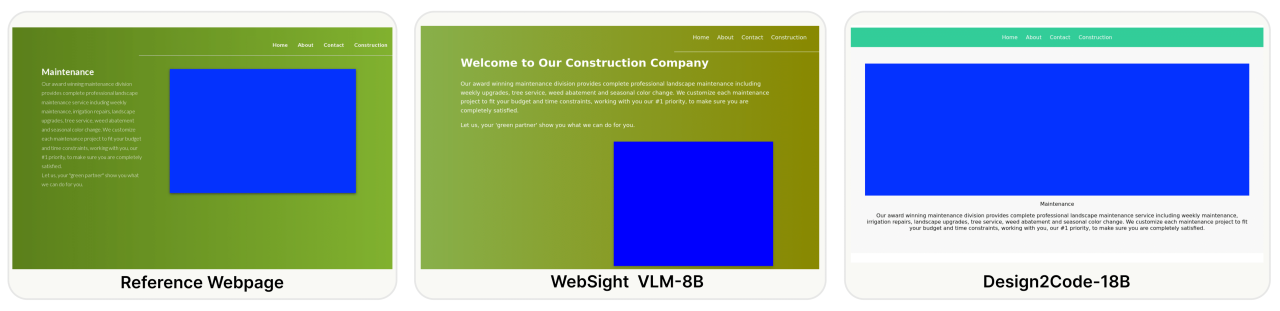
Additional GPT-4V Generation Examples
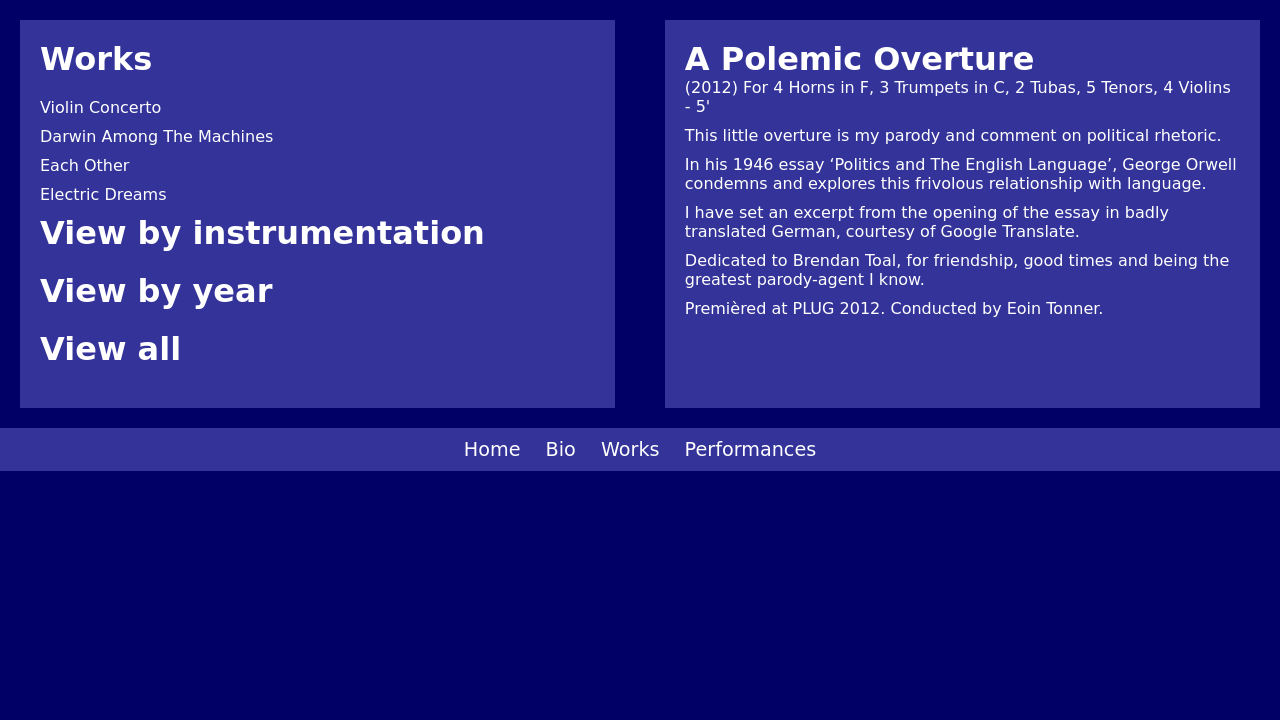
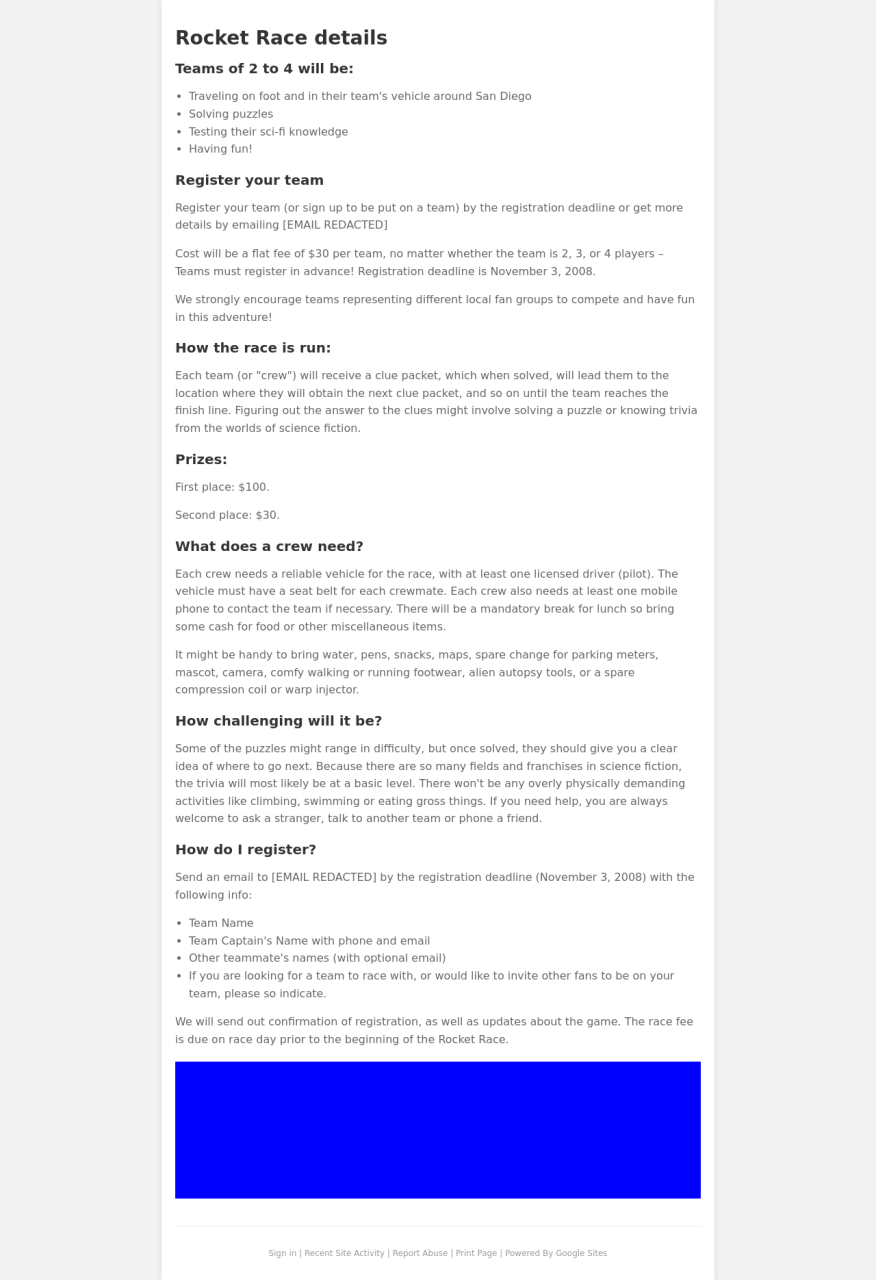
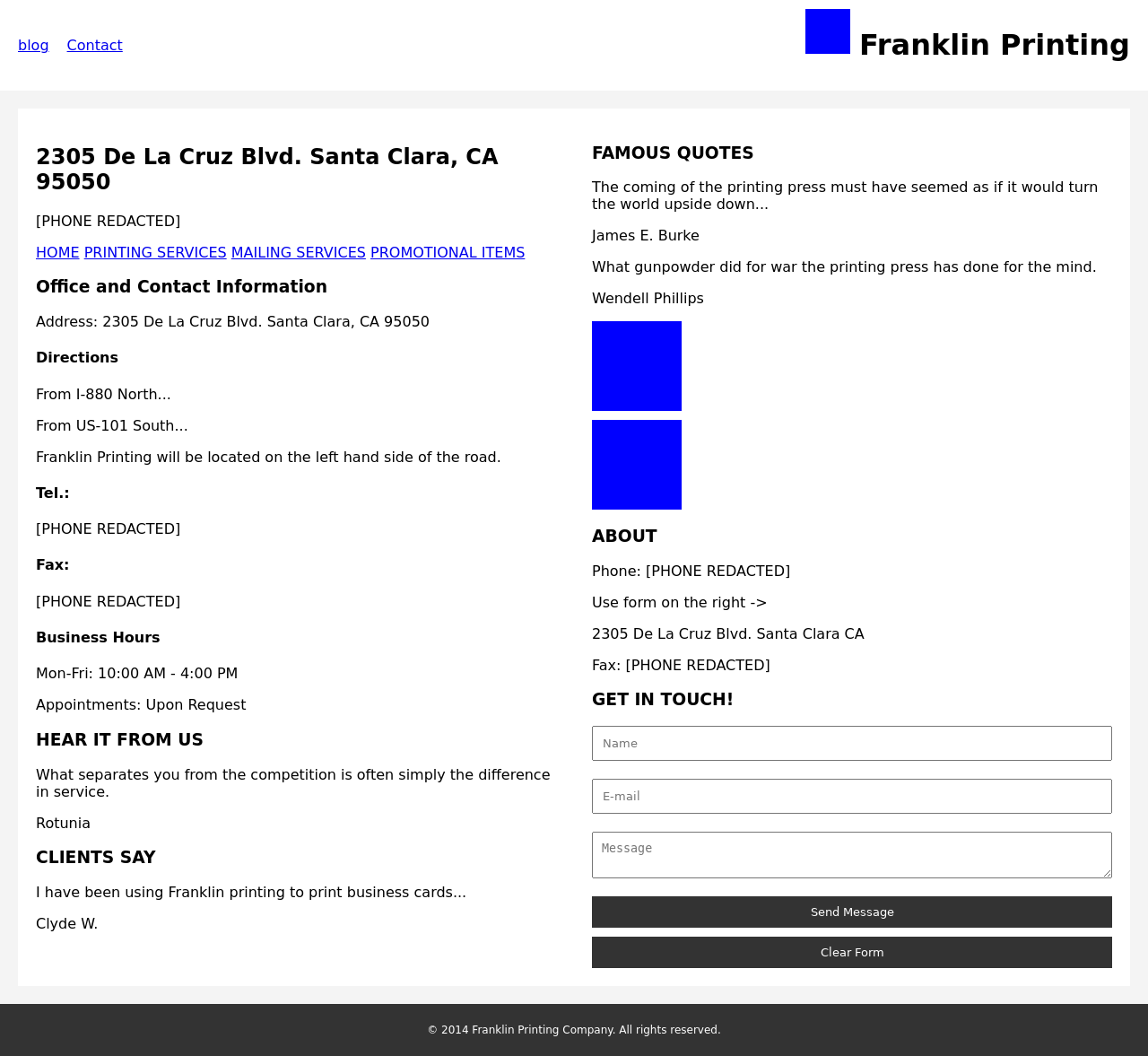
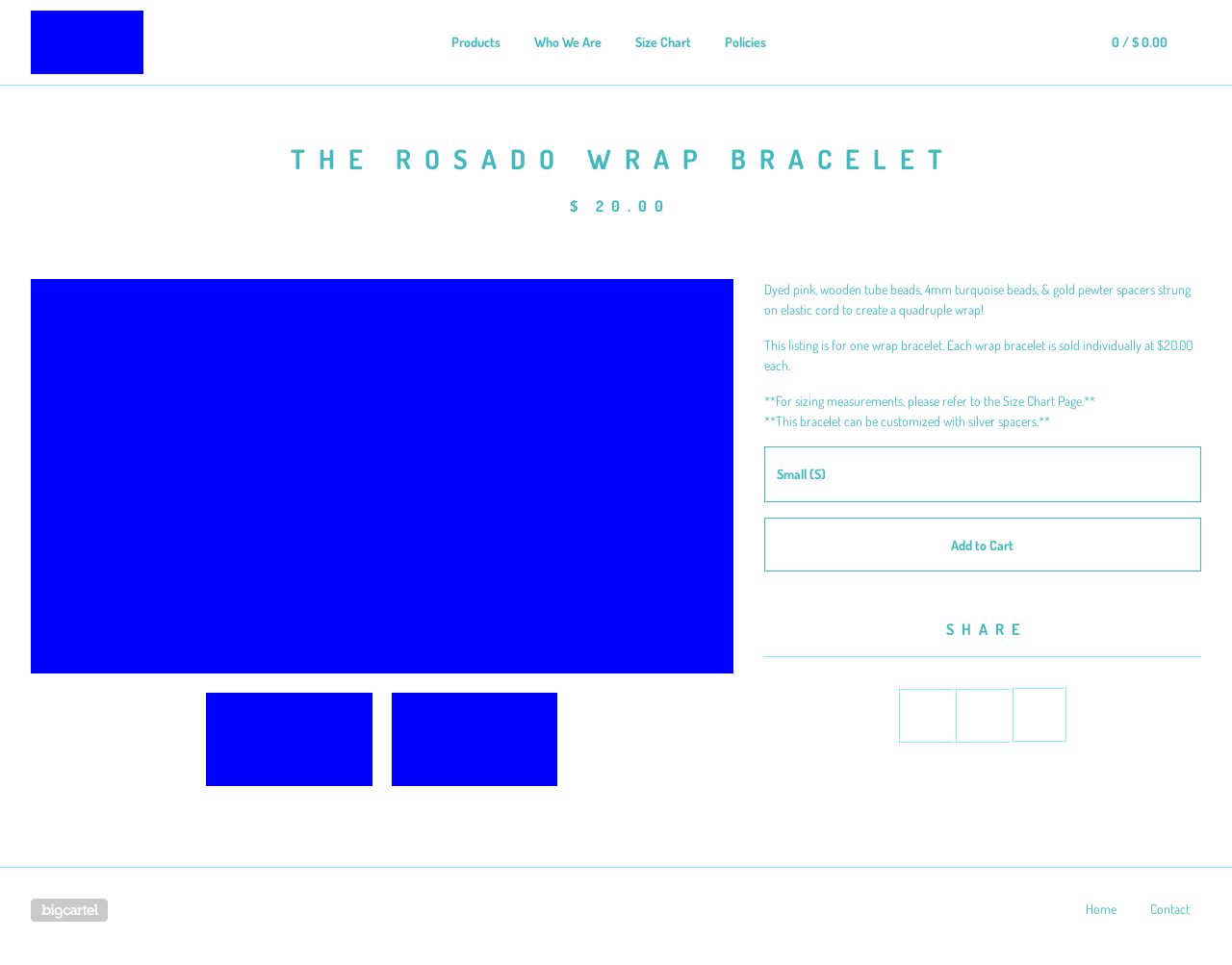
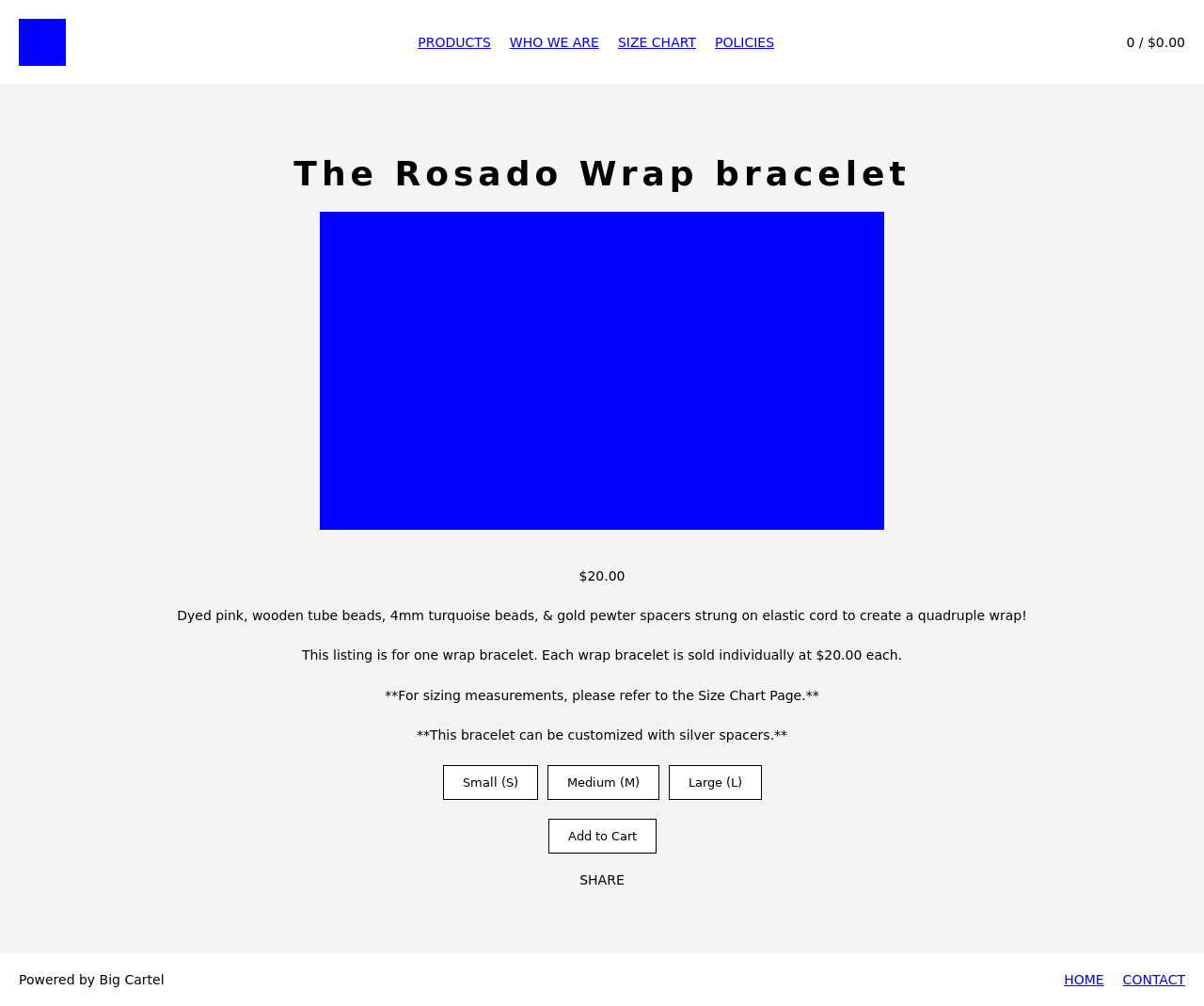
We present more examples of GPT-4V generated webpages in comparison with the original reference webpages. The original designs are on the left and the GPT-4V generated webpages are on the right. You can judge for yourself whether GPT-4V is ready to automate building webpages.



BibTeX
@misc{si2024design2code,
title={Design2Code: How Far Are We From Automating Front-End Engineering?},
author={Chenglei Si and Yanzhe Zhang and Zhengyuan Yang and Ruibo Liu and Diyi Yang},
year={2024},
eprint={2403.03163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Usage and License Notices
The data, code and model checkpoint are intended and licensed for research use only. Please do not use them for any malicious purposes.
The benchmark is built on top of the C4 dataset, under the ODC Attribution License (ODC-By).
This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
This source code of this website is borrowed from Nerfies.
Comments (0)